Distributed Computing for Plasma Simulations
Registration Fee: $650 (Regular), $325 (Student)
20% discount to former students!
Register now!
Overview
In this course we develop parallel PIC plasma simulation codes that utilize power of multiple cores, multiple computers, and even graphics cards to obtain results faster or to tackle problems larger than possible with a single CPU serial code. We will specifically address multithreading, distributed computing with MPI, and GPU programming with CUDA. We will apply these techniques to the 3D Cartesian flow past a sphere simulation from PIC Fundamentals. The course will primarily utilize C/C++ but will also introduce options available in Python and external HPC libraries.
Course Objectives
At the conclusion of this eight week online course, you should have a solid understanding of code parallelization techniques, and be able to develop codes utilizing multithreading, MPI, and CUDA.
Course Format
The course consists of eight lectures that were conducted through Citrix® GoToMeeting. All registered students receive access to a student area where the course materials are posted. These materials include recordings of the lectures, copy of the lesson slides, and example codes. The course also includes optional weekly homework assignments, which will need to be completed in order to receive a certificate of completion.
Course Outline
- Lesson 1 (Review, profiling, multithreading): We start the course by reviewing the 3D ES-PIC for flow past a sphere from PIC Fundamentals. We then learn how to use a profiler to determine which parts of the code are taking long time to run. We next see how to develop multithreaded C++ programs that utilize multiple cores found on all modern CPUs.
- Lesson 2 (Multithreading, AWS, MPI overview): We add multithreading to the sphere code and characterize performance versus the serial code. Next we learn how to use Amazon Web Services to create a computational cluster. We then learn basics of MPI, and use it to develop a sample distributed computing program that runs on multiple computers concurrently.
- Lesson 3 (MPI Particle Push): In this lecture we develop the MPI version of particle pushing. We learn how to pass particles from one computer to another, and how to combine data from different processors. We compare two approaches: domain decomposition and uniform distribution among processors.
- Lesson 4 (MPI Field Solver): Next we develop a parallel Poisson solver. This will give us a complete MPI PIC code. We run the code with several different processor counts to characterize parallel performance.
- Lesson 5 (Advanced MPI, intro to CUDA): We start by reviewing some additional MPI commands. Next, we learn about important differences between CPUs and GPUs. We then learn about GPU programming with CUDA and develop an example code running on the GPU. We also briefly compare CUDA with OpenCL.
- Lesson 6 (GPU Field Solver): In this lecture, we see how we can utilize the GPU to solve the Poisson’s equation. We investigate using open source matrix math libraries optimized for CUDA and compare them against our implementation.
- Lesson 7 (GPU Particle Push): Next we cover using CUDA to push particles. We also discuss cases that are not suitable for GPUs. We combine the particle pusher with the GPU field solver.
- Lesson 8 (Combining CPU+GPU, visualization): We use this lesson to review lessons learned, and how to utilize combination of multithreading, MPI, and CUDA to best utilize the available resources. We also cover using GPUs to add basic rendering capability to our codes.
Examples

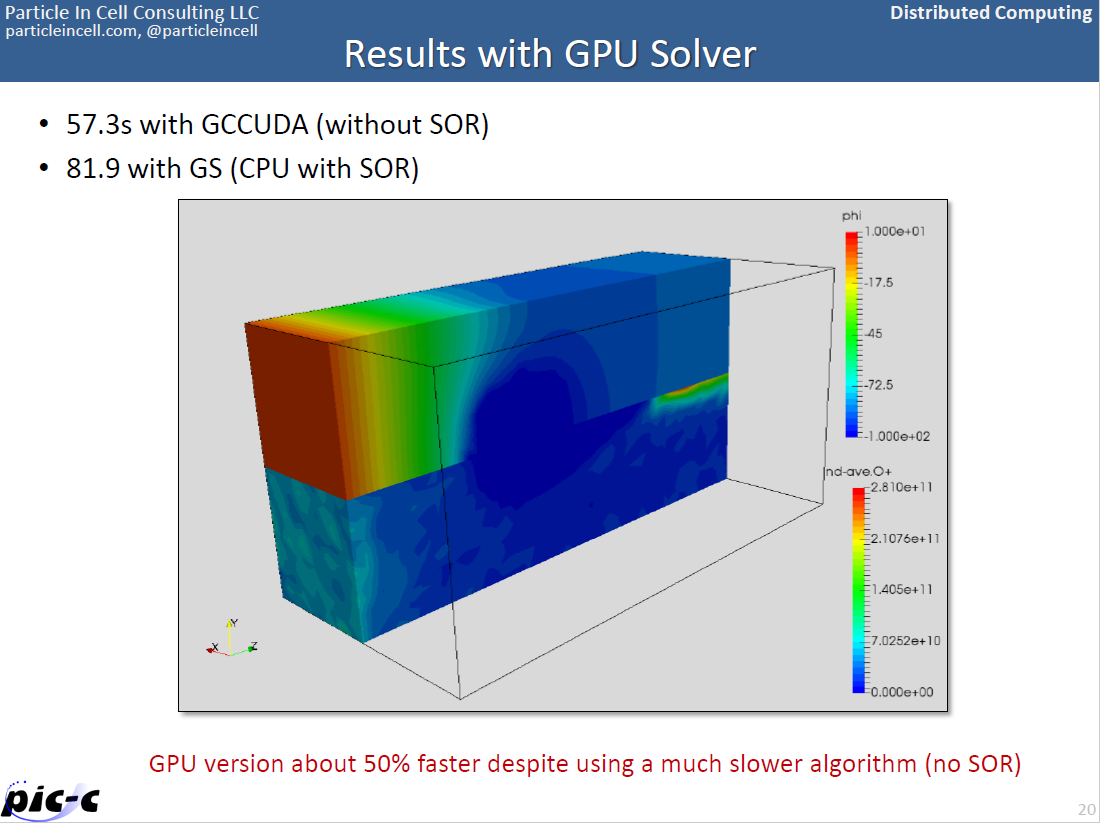
Assignments
- Homework 1 asks you to review a recent journal paper discussing parallel computations
- Homework 2 involves writing a multithreaded code scatter particles to the mesh
- Homework 3 gives you a chance to compute the Julia set (a fractal) using an MPI code
- Homework 4 asks you to parallelize the 1D sheath code from PIC Fundamentals using MPI
- Homework 5 involves writing a CUDA program to estimate value for cosine from MacLaurin series
- Homework 6 asks you to parallelize the 1D sheath code using CUDA
Instructor
The instructor, Dr. Lubos Brieda, is the founder and president of Particle In Cell Consulting, LLC, a Los Angeles-based company specializing in providing tools and services for the plasma physics and rarefied gas communities. Dr. Brieda has over 10 years of experience developing PIC codes for a wide range of applications, including electric propulsion, space environment interactions, surface processing, and plasma medicine. His teaching experience includes the position of a Lecturer at the George Washington University.
Requirements
Completion of the PIC Fundamentals course, or an existing understanding of the Particle In Cell (PIC) method, including particle motion, mesh interpolation, and field solving. In addition, all students are expected to have a basic understanding of numerical techniques, plasma and gas dynamics, and computer programming. The lectures and demonstration programs will utilize the C++ programming language. Students need to have access to a computer with a compiler of choice. We will use Amazon Web Services (AWS) for the cluster environment. Computer with an Nvidia CUDA compatible graphics card is recommended but not required as we will run some CUDA cases on AWS. Computer with Internet access will be needed to access the lectures and course material. The course will be conducted in English.